Sterowanie procesami w Node JS
Naucz się jak tworzyć i zabijać podprocesy w Node JS, dynamicznie zarządzać ich ilością i prowadzić z nimi dwustronną komunikację.

Daniel Gustaw
• 16 min read
W tym wpisie nauczymy się jak tworzyć i kończyć podprocesy w Node JS oraz jak przesyłać między nimi dane.
Jeśli program wykonuje ciężkie obliczenia, ale nie jest zrównoleglony, stan Twojego procesora może wyglądać tak:

Dlatego warto zgłębić ten temat niezależnie od języka, w którym piszesz.
Artykuł będzie podzielony na 3 części:
- sterowanie procesem za pomocą
readline - tworzenie i zabijanie podprocesów
- komunikacja między procesami
W pierwszych dwóch napiszemy skrypt do symulowania obciążenia rdzeni procesora. W ostatniej zrównoleglimy atak brutforce na hasło.
Na końcu przeanalizujemy skalowalność napisanego programu.
Sterowanie procesem z readline
Chcemy napisać program, w którym wciskając klawisz na klawiaturze, będziemy ustawiać ile rdzeni procesora, ma zostać obciążonych. Zaczniemy od przechwytywania zdarzeń z klawiatury w czasie rzeczywistym.
Pozwoli nam na to moduł readline dostarczający interfejs do zapisu i odczytu danych ze strumieni takich jak
klawiatura - process.stdin.
Zaczniemy od importu tego modułu
const readline = require('readline');Następnie ustawiamy emitowanie zdarzenia z readline na naciśnięcie przycisku na klawiaturze poleceniem
readline.emitKeypressEvents(process.stdin);Sam readline może pracować z różnymi strumieniami. Tą linią wskazujemy mu, żeby nasłuchiwał na klawiaturę. Od razu
ustawiamy mod na raw
process.stdin.setRawMode(true);Pozwala to odczytywać z klawiatury znak po znaku z osobno załączanymi modyfikatorami jak ctrl czy shift. Jednocześnie
ten tryb wymusza samodzielne obsłużenie wyłączenia procesu przez ctrl+c. Więcej na temat trybów strumieni i
podłączania terminala do procesu możemy przeczytać w dokumentacji:
Readline | Node.js v16.5.0 Documentation | Node.js v16.5.0 Documentation
TTY | Node.js v16.5.0 Documentation | Node.js v16.5.0 Documentation
Tymczasem w naszym programie kolejne linie pozwolą obsłużyć odczyt znaków:
process.stdin.on('keypress', (str, key) => {
if (key.ctrl && key.name === 'c') {
process.exit();
} else {
console.log('typed char', key.name);
}
});Znak zapisany w key jest obiektem o następujących kluczach
{ sequence: 'v', name: 'v', ctrl: false, meta: false, shift: false }W prezentowanym kodzie obsługujemy zamknięcie procesu kombinacją ctrl+c oraz wypisanie w konsoli znaku wybranego na
klawiaturze. Wpisywanie kolejnych znaków będzie za każdym razem pokazywało je w terminalu.

Następnym krokiem jest zastąpienie wypisywania znaków przez tworzenie lub kasowanie procesów obciążających procesor.
Tworzenie i zabijanie procesów w Node JS
W Node JS możemy bardzo łatwo tworzyć podprocesy i zarządzać nimi. Do zarządzania podprocesami możemy użyć
modułu child_process. Importujemy go jak poprzedni moduł
const cp = require('child_process');Następnie tworzymy tablicę, do której będziemy zapisywali referencje do tworzonych procesów.
const forks = [];Jeśli zapomnielibyśmy o nich przy zamykaniu programu to stały by się one procesami zombie - czyli takimi, które żyją
nadal i bez nadzoru pożerają zasoby komputera.

Aby je usunąć, przed zamknięciem naszego skryptu piszemy kod:
if (key.ctrl && key.name === 'c') {
while (forks.length > 0) {
forks[forks.length - 1].kill()
forks.pop()
}
process.exit();
} else {W przypadku wybrania innych przycisków niż c w obecności ctrl odczytamy wartość liczbową tego przycisku i na jej
podstawie dodamy lub zabijemy odpowiednią liczbę procesów aby ich ilość równa była tej liczbie.
if (!Number.isNaN(parseInt(key.name,32))) {
const req = parseInt(key.name,32);
if (forks.length < req) {
while (forks.length < req) {
const n = cp.fork(`${__dirname}/bomb.js`);
forks.push(n)
}
}
if (forks.length > req) {
while (forks.length > req) {
forks[forks.length - 1].kill()
forks.pop()
}
}
console.log('processes PIDs', forks.map(f => f.pid));
}Dziwić może wybór systemu liczbowego 32. Jednak jest to wygodny system, jeśli założymy, że za pomocą jednego klawisza
chcemy wskazać niewielką, lecz przekraczającą 10 liczbę.
Do zmiennej req trafia wymagana liczba procesów, a dzięki cp.fork lub kill tworzymy i zabijamy brakujące lub
nadmiarowe procesy.
Do złożenia całości brakuje nam jedynie zawartości pliku bomb.js. Tam mogłyby być jakiekolwiek operacje zużywające moc
obliczeniową. W naszym przypadku jest to
let result = 0;
while (true) {
result += Math.random() * Math.random();
}czyli kod napisany tylko po to, żeby symulować obciążenie.
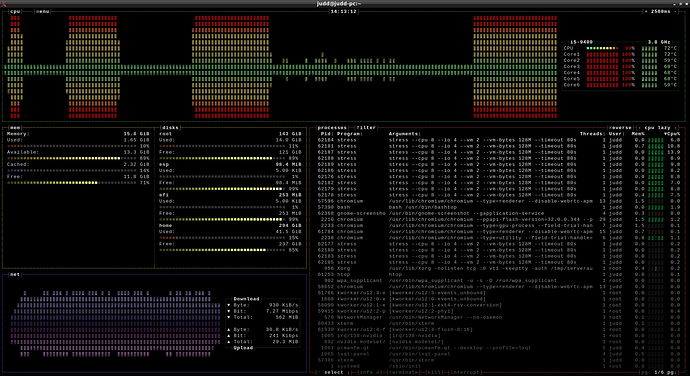
Po włączeniu programu i wyborze kilku opcji obciążenia widzimy, jak procesy są tworzone oraz kasowane. Dzięki htop
możemy zobaczyć, jak w tym czasie zmienia się zużycie procesora.

Nawet ładniejszy interfejs do monitoringu procesora ma bashtop, ponieważ wyświetla również historyczne zużycie. Na
screenshocie poniżej widzimy, jak modyfikując ilość procesów w naszym programie mogłem symulować różne poziomy obłożenia
procesora zadaniami.

Oraz jak wyglądało wykorzystanie rdzeni, kiedy wybrałem opcję utworzenia 16 procesów.

Tego programu możemy używać do symulowania obciążenia. W pliku bomb.js możemy zastąpić losowanie liczb operacją
wysyłania żądań http lub zużywania innych zasobów, na przykład pamięci operacyjnej lub dysku.
Zrównoleglony atak brute-force na hasło
Do hash owania haseł w historii stosowano różne metody. Obecnie najbardziej popularny jest bcrypt, ale bardzo mocną
pozycję zajmuje też nowocześniejszy argon2i. Upraszczając różnica między nimi polega na tym, że łamanie bcrypta wymaga
dużej mocy obliczeniowej, a argona można tak skonfigurować, aby wymagane było posiadanie dużej ilości pamięci
operacyjnej. W przypadku tego pierwszego zasobu, możemy łatwo kupić moc obliczeniową w bardzo dużych ilościach,
dodatkowo nasze możliwości łamania haseł podnoszą układy graficzne i procesory strumieniowe. Jednak przy łamaniu argona
znacznie trudniej jest zgromadzić wymagane do tego ilości pamięci operacyjnej w ramach jednej maszyny. Mój bardzo krótki
opis warto rozszerzyć lekturą artykułu:
Password Hashing: PBKDF2, Scrypt, Bcrypt and ARGON2
W dalszej części wpisu pokażemy jak stosowanie wielu rdzeni przyśpiesza łamanie hasła zahashowanego algorytmem bcrypt.
Napiszemy kod do generowania hashu hasła, złamiemy go używając jednego rdzenia, a następnie napiszemy ten sam kod korzystając z podporcesów którym będziemy zlecać sprawdzanie kolejnych fraz.
Generowanie hasha hasła za pomocą bcrypt
Wymagana jest do tego instalacja paczki bcrypt:
npm init -y && npm i bcryptHasło wygenerujemy za pomocą skryptu generate_hash.js, który przyjmuje argument będący hasłem i do pliku .pass
zapisuje jego hash.
const fs = require('fs')
const bc = require('bcrypt')
const main = async () => {
return bc.hash(process.argv[2] || 'pass', 11)
}
main().then(p => {
fs.writeFileSync(`${__dirname}/.pass`, p);
console.log(p)
}).catch(console.error);Łamanie hasła metodą brute force w jednym wątku
W ataku brute-force kluczowy jest zestaw znaków, na których rozpinamy ciągi, które będziemy sprawdzać. Użyjemy
standardowego alfabetu od a do z. Będziemy go składać z samym sobą generując kolejne sekwencje znaków do
sprawdzenia. Proces ich generowania i przetwarzania można umieścić w funkcji rekurencyjnej, ale przez to tracimy szansę
na wygodne sterowanie kolejnością. Zamiast tego zastosujemy prostą kolejkę trzymaną w pamięci operacyjnej. Nie będzie
ona rozładowywana, ponieważ rozładowywanie jej od przodu powodowało by zmianę indeksacji wewnątrz kolejki. Opisywałem
już jak złe może to mieć skutki dla wydajności w artykule:
Ile rodzin zmieści się w samolocie - zadanie z algorytmiki
Porównujemy dwa rozwiązania zadania polegającego na zliczaniu wolnych zestawów przyległych miejsc. Dowiesz się jak używać Profilowania i jak wielką różnicę robi użycie pop oraz shift na tablicach w js.

Zamiast rozładowywać kolejkę będziemy odczytywać z niej wartości za pomocą zmiennego indeksu, który będzie przesuwał się wzdłuż niej. Schemat blokowy programu, który napiszemy jest następujący:

Jego kod to:
const fs = require('fs');
const bc = require('bcrypt');
const alphabet = String.fromCharCode(...Array(123).keys()).slice(97);
const hash = fs.readFileSync(`${__dirname}/.pass`).toString()
const chalk = require('chalk')
let i = 0;
const s = new Date().getTime();
const n = () => new Date().getTime() - s;
let found = false;
const que = [];
async function check(input) {
if (found) return;
const r = await bc.compare(input, hash)
console.log(`${i}\t${input}\t${n()}\t${r}\t${que.length}`)
if (r) {
console.log(chalk.green(`FOUND: "${input}"`))
found = true;
process.exit();
}
for (let n of alphabet) {
que.push(input + n);
}
}
async function processQue() {
const phrase = que[i++]
await check(phrase)
}
const main = async () => {
while (!found) {
await processQue()
}
}
console.log(`i\tinput\tn()\tr\tque.length`)
check('').then(() => main()).catch(console.error)Do działania wymagana jest paczka chalk, która pozwala na łatwe kolorowanie tekstu:
npm i chalkPrzetestujmy nasz program.
Na początku wygenerujemy hasło. Zdecydujemy się na “ac”, ponieważ jest proste i szybko je złamiemy
node generate_hash.js acNastępnie włączamy nasz program i widzimy jak po kolei sprawdza hasła z kolejki
time node force-single.js
W kolumnach mamy kolejno indeks, sprawdzaną sekwencję, czas od włączenia programu w milisekundach, informację, czy hasło pasuje do hashu oraz aktualną długość kolejki.
Jeśli martwi Cię, że kolejka rośnie zbyt szybko i marnuje to dużo mocy, możemy zobaczyć, jak zachowa się program po zastąpieniu linii
const r = await bc.compare(input, hash)przez
const r = i >= 29 // await bc.compare(input, hash)Okaże się wówczas, że czas wykonania skryptu spadnie z 7.27 sekundy do 0.17 sekundy.
node force-single.js 0.17s user 0.03s system 103% cpu 0.188 totalCo znaczy, że jedynie 2.3% mocy obliczeniowej jest przeznaczane na operacje inne niż samo porównywanie haseł.
Wykorzystanie podprocesów do podniesienia wydajności
Ponieważ sprawdzanie zgodności hasła i hashu jest operacją intensywnie korzystającą z procesora spodziewamy się znacznego wzrostu wydajności tego zadania jeśli użyjemy do niego wielu rdzeni jednocześnie. Z tego względu przepiszemy nasz program tak, aby główny proces zamiast wykonywać sprawdzanie haseł zajmował się obsługą kolejki i zlecaniem sprawdzania podrzędnym procesom.

Schemat naszego programu dzieli się na proces główny oraz podprocesy. W procesie głównym tworzona jest lista procesów podrzędnych, kolejka oraz nasłuchy na wiadomości z podprocesów. Na końcu każdy podproces dostaje do wykonania zadanie z kolejki. Podprocesy po ich wykonaniu zgłaszają się do głównego wątku z odpowiedzą, a ten podnosi indeks i przydziela im nowe zadania. Dzieje się tak aż do znalezienia poprawnego hasła.

Warto zwrócić uwagę na to, że niezależne dzieci będą wykonywały zadania z różną prędkością, co wpłynie na kolejność zgłaszania odpowiedzi. Przykładowy output programu to:

Kod dzieli się na dwa pliki:
- force-child.js - proces główny używający dzieci
- force-fork.js - podproces do sprawdzania haseł przez bcrypt
Zaczniemy analizę procesu głównego - force-child.js. Program startuje od zdefiniowania alfabetu oraz zmiennych
pomocniczych do indeksowania i liczenia czasu.
const cp = require('child_process');
const fs = require('fs');
const chalk = require('chalk')
const alphabet = String.fromCharCode(...Array(123).keys()).slice(97);
const forks = [];
let i = 0;
const s = new Date().getTime();
const n = () => new Date().getTime() - s;
let found = false;Następnie wypełniamy kolejkę alfabetem
const que = alphabet.split('');Funkcja check w jednowątkowej wersji programu dostawała frazę, sprawdzała ją i rozszerzała kolejkę. Tym razem oprócz
frazy, argumentem będzie podproces wybrany do wykonania sprawdzenia - f. Zamiast używać bcrypt bezpośrednio wyślemy
podprocesowi żądanie przetworzenia frazy i rozbudujemy kolejkę.
function check(input, f) {
if (found) return;
f.send(input);
for (let n of alphabet) {
que.push(input + n);
}
}Pozbyliśmy się tu słowa async przez co nie musimy czekać na wykonanie tej funkcji. Jest to proste oddelegowanie
zadania. Kluczowym elementem tego kodu jest wysyłka wiadomości do podprocesu realizowana przez funkcję send wykonaną
bezpośrednio na podprocesie.
Kolejna funkcja processQue służy nam do wykonania pojedynczego taktowania na kolejce
function processQue(f) {
const phrase = que[i++]
check(phrase, f)
}Jest bardzo krótka i jej głównym zadaniem zapobieganie duplikacji logiki odpowiedzialnej za iterowanie po kolejce.
Główną funkcją programu jest main i odpowiada za ustawienie nasłuchów na odpowiedzi z podprocesów oraz zlecenie im
początkowych zadań, które pozwalają wejść w pętlę komunikacji między nimi.
const main = async () => {
forks.forEach(f => {
f.on('message', ({input, r}) => {
console.log(`${i}\t${input}\t${n()}\t${r}\t${que.length}\t${f.pid}`)
if (r) {
console.log(chalk.green(`FOUND: "${input}"`))
found = true;
fs.appendFileSync('logs.txt', `${forks.length},${n()}\n`)
while (forks.length > 0) {
forks[forks.length - 1].kill()
forks.pop()
}
process.exit();
} else {
processQue(f);
}
});
processQue(f);
})
}Zanim wywołamy funkcję main wymagane jest powołanie do życia procesów w tablicy forks:
while (forks.length < (process.argv[2] || 15)) {
const n = cp.fork(`${__dirname}/force-fork.js`);
forks.push(n)
}Zalecaną ich liczbą jest wartość zbliżona do ilości wątków procesora ale mniejsza od niej, tak, aby proces główny nie był blokowany.
Na końcu drukujemy informacje o programie, nazwy kolumn i startujemy funkcję main
console.log(chalk.blue(`Run using ${forks.length} child processes`))
console.log(`i\tinput\tn()\tr\tque.length\tpid`)
main().catch(console.error)Drugi plik - force-fork.js jest znacznie prostszy i zawiera jedynie odczytanie hasha oraz oczekiwanie na zadania.
Kiedy je dostaje sprawdza testowane hasło bcryptem po czym odsyła wynik tym samym kanałem komunikacji.
const fs = require('fs');
const bc = require('bcrypt');
const hash = fs.readFileSync(`${__dirname}/.pass`).toString()
process.on('message', (input) => {
bc.compare(input, hash).then((r) => {
process.send({r, input});
})
});Analiza skalowalności
Wnikliwy czytelnik zapewne zauważył niepozorną, ale ważną dla dalszej części artykułu linię kodu:
fs.appendFileSync('logs.txt', `${forks.length},${n()}\n`)Wykonuje się ona po znalezieniu hasła i załącza do pliku logs.txt ilość podprocesów oraz czas znalezienia hasła. Dane
do tego pliku zostały dostarczone dzięki wykonaniu podwójnej pętli w bashu
for j in $(seq 1 20); do for i in $(seq 1 25); do time node force-child.js $i; sleep 4; done; done;Oraz później rozbudowania tych wyników o wyższą liczbę procesów
for j in $(seq 1 5); do for i in $(seq 1 50); do time node force-child.js $i; sleep 4; done; done;Zgodnie z Ogólnym Prawem Skalowania spodziewamy się wzrostu wydajności do pewnego etapu ( koło 15 rdzeni ) i późniejszego spadku związanego z opóźnieniami spowodowanymi wzajemnym blokowaniem się podprocesów.
Uniwersalne prawo skalowania
Jeśli nie słyszałeś o uniwersalnym prawie skalowania, to szybko wprowadzę Cię do tego tematu. Chodzi o to, że w idealnym
świecie, gdyby systemy były skalowalne liniowo, to znaczyło by, że dołożenie n razy więcej zasobów podnosi wydajność
lub przepustowość systemu n razy. Taką sytuację może obrazować rysunek:

Takich sytuacji nie spotyka się jednak w świecie rzeczywistym. Zawsze bowiem występuje pewna nieefektywność związana z
przydzielaniem danych do węzłów (serwerów lub wątków) oraz z ich zbieraniem. Opóźnienia związane z przydzielaniem i
odbieraniem danych nazywa się serializacją, czasami można spotkać termin contention:

Uwzględnienie tego zjawiska prowadzi do modelu Amdahl`a. Okazuje się jednak, że jest on niewystarczający dla większości
systemów IT ponieważ całkowicie pomija drugi główny czynnik ograniczający skalowanie - komunikację między
procesami - crosstalk. Graficznie można ją przedstawić tak:

O ile serializacja ma koszt proporcjonalny do ilości węzłów, to komunikacja jest proporcjonalna do ich kwadratu - tak jak liczba przekątnych wielokąta do ilości kątów

Na wykresie widzimy krzywe porównujące wpływ ilości węzłów na wydajność w systemu według tych trzech modeli.

Dobre (50 stron) opracowanie na ten temat znajduje się pod linkiem:
https://cdn2.hubspot.net/hubfs/498921/eBooks/scalability_new.pdf
Zestawienie danych pomiarowych z modelem USL
Zebrane dane to ilości wątków oraz czasy wykonywania programu. Ładujemy do do programu Mathematica komendą:
load = Import["/home/daniel/exp/node/logs.txt", "Data"];Ponieważ chcemy rozważać wydajność, a nie czas wykonywania odwracamy drugą kolumnę poleceniem
loadEff = {#[[1]], 1/#[[2]]} & /@ load;Najbardziej sensowną jednostką jest normalizacja względem czasu wykonania dla jednego podprocesu. Pozwoli nam to widzieć zysk z dokładania kolejnych procesów. Średnią z tych czasów liczymy dzięki poleceniu
firstMean = GroupBy[loadEff // N, First -> Last, Mean][[1]];Następnie dopasowujemy model:
nlm = NonlinearModelFit[{#[[1]], #[[2]]/firstMean} & /@
loadEff, \[Lambda] n/(1 + \[Sigma] (n - 1) + \[Kappa] n (n -
1)), {{\[Lambda], 0.9}, {\[Sigma], 0.9}, {\[Kappa],
0.1}}, {n}]I zestawiamy go z wykresem listy punktów pomiarowych
Show[ListPlot[{#[[1]], #[[2]]/firstMean} & /@ loadEff],
Plot[nlm[s], {s, 0, 50}, PlotStyle -> Orange, PlotRange -> All],
AxesLabel -> {"processes", "gain of efficiency"}, ImageSize -> Large,
PlotLabel -> "Gain of efficiency relative to single process"]
Warto pokazać tu bardzo ładny wzór na teoretyczne maksimum
Solve[D[\[Lambda] n/(1 + \[Sigma] (n - 1) + \[Kappa] n (n - 1)),
n] == 0, n]
Wyliczona numerycznie
NSolve[D[Normal[nlm], n] == 0, n]optymalna ilość procesów to 14.8271. Kilka akapitów wcześniej pisałem, że zaleca się wartość nieznacznie niższą niż
ilość dostępnych wątków - u mnie było ich 16.
Procesy, Workery i Klastry w Node JS
Ten artykuł skupiał się na procesach opisanych w dokumentacji pod linkiem
Process | Node.js v16.5.0 Documentation | Node.js v16.5.0 Documentation
Pokazaliśmy w nim jak tworzyć podprocesy, zabijać je. Jak dynamicznie zarządzać ilością podporcesów i prowadzić z nimi dwustronną komunikację. Na końcu zestawiliśmy skalowalność łamania haseł metodą bruteforce z przewidywaniami uniwersalnego prawa skalowania.
Jednak ten temat został przez nas jedynie delikatnie muśnięty. Nie pisałem nic na temat klastrów opisanych tutaj:
Cluster | Node.js v16.5.0 Documentation | Node.js v16.5.0 Documentation
Ani workerów, które również mają osobny rozdział do dokumentacji
Worker threads | Node.js v16.5.0 Documentation | Node.js v16.5.0 Documentation
Zachęcam Was do samodzielnej lektury dokumentacji Node JS i projektowania własnych eksperymentów.
Other articles
You can find interesting also.
![Ostatnie wystąpienie [Wyszukiwanie liniowe] łatwe](https://preciselab.fra1.digitaloceanspaces.com/blog/img/thumb_f0cf18ae-5174-47c0-81af-cb479a0c36b3.avif)
Ostatnie wystąpienie [Wyszukiwanie liniowe] łatwe
Znajdź i wydrukuj indeks ostatniego wystąpienia elementu w tablicy.
Daniel Gustaw
• 2 min read

Tutorial dla twórców pakietów ESM + CommonJS
W społeczności JS trwa intensywna debata na temat porzucenia CommonJS lub korzystania z podwójnych pakietów. Zgromadziłem kluczowe linki i napisałem poradnik dotyczący publikacji podwójnych pakietów.
Daniel Gustaw
• 7 min read

Fetch, Promise i Template String na przykładzie Listy Zadań w JavaScript
Ten prosty projekt jest doskonałym wprowadzeniem do programowania w JavaScript. Nacisk kładzie się na elementy ES6 i frontend.
Daniel Gustaw
• 13 min read